

And more snakes.


Deploying modern web apps – with all the provisions needed to be fast and secure while easily updateable – has become so hard that many developers don’t dare do it without a PaaS (platform-as-a-service). But that’s ridiculous. Nobody should have to pay orders of magnitude more for basic computing just to make deployment friendly and usable. That’s a job for open source, and Rails 8 is ready to solve it. So it’s with great pleasure that we are now ready with the final version of Rails 8.0, after a successful beta release and several release candidates!
Here are all the major new bits in box:
Rails 8 comes preconfigured with Kamal 2 for deploying your application anywhere. Whether to a cloud VM or your own hardware. Kamal takes a fresh Linux box and turns it into an application or accessory server with just a single “kamal setup” command. All it needs is the IP addresses for a set of servers with your SSH key deposited, and you’ll be ready to go into production in under two minutes.
Kamal can do this so easily because Rails already comes with a highly efficient and tuned Dockerfile for turning your application into a production-ready container image out of the box. All you need to bring is your own container registry account, like Docker Hub or GitHub, for storing the images.
In Rails 8, this Dockerfile has been upgraded to include a new proxy called Thruster, which sits in front of the Puma web server to provide X-Sendfile acceleration, asset caching, and asset compression. This means there’s no need to put an Nginx or any other web server in front. The default Rails container is ready to accept traffic from the internet immediately.
Kamal 2 also includes a proxy, this time a bespoke unit called Kamal Proxy to replace the generic Traefik option it used at launch. This proxy provides super fast zero-downtime deploys, automated SSL certificates via Let’s Encrypt, and support for multiple applications on a single server without any complicated configuration.
Together with a revised strategy for handling secrets (featuring built-in integration for 1password, Bitwarden, and LastPass) and a new aliases feature to get commands like “kamal console” to start a remote Rails console session, it provides a complete package for handling not just the deployment but the operation of your application in production.
Kamal 2 was lead by Donal McBreen and Kamal Proxy + Thruster was created by Kevin McConnell, both from 37signals.
Part of making Rails easier to deploy is to cut down on the number of accessory services required to get going. In the past, Rails needed either MySQL or PostgreSQL as well as Redis to take full advantage of all its features, like jobs, caching, and WebSockets. Now all of it can be done with SQLite thanks to a trifecta of new database-backed adapters named Solid Cable, Solid Cache, and Solid Queue.
These adapters are all created from the same premise: Disks have gotten fast enough that we don’t need RAM for as many tasks. This allows us to reap the simplification benefits of SSD and NVMe drives being orders of magnitude faster than good-old spinning rust.
Solid Cable replaces the need for Redis to act as the pubsub server to relay WebSocket messages from the application to clients connected to different processes. It uses fast polling, but it’s still almost as quick as Redis, when run through the same server on SQLite. Beyond plenty fast enough for most applications. As a bonus, Solid Cable retains the messages sent in the database for a day by default, which may ease debugging of tricky live update issues.
Solid Cable has been created by Nick Pezza from Working Not Working.
Solid Cache replaces the need for either Redis or Memcached for storing HTML fragment caches in particular. In addition to getting rid of the accessory service dependency, it also allows for a vastly larger and cheaper cache thanks to its use of disk storage rather than RAM storage. This means your cache can live longer and cover even more requests out the plank of the 95th or 99th percentile. Additionally, this cache can be encrypted and managed by an explicit retention limit (like 30 or 60 days). Making it easier to live up to modern privacy policies and expectations.
Solid Cache has been in production at Basecamp for well over a year where it stores 10 terabytes of data, enables a full 60-day retention window, and cut the P95 render times in half after it’s introduction.
Solid Cache was created by Donal McBreen from 37signals.
Solid Queue replaces the need for not just Redis, but also a separate job-running framework, like Resque, Delayed Job, or Sidekiq, for most people. For high-performance installations, it’s built on the new FOR UPDATE SKIP LOCKED mechanism first introduced in PostgreSQL 9.5, but now also available in MySQL 8.0 and beyond. For more modest needs, it also works with SQLite, which makes it ideal for that no-dependency path to the first HELLO WORLD dopamine hit you get from seeing your work in production right away.
Solid Queue can either run as a puma plugin, which is the default on a single-server installation, or by using the new bin/jobs command for starting a dedicated dispatcher. It’s possible to run multiple dispatchers dealing with dedicated queues according to bespoke performance tuning all with a flexible configuration scheme that asks for no tweaking out of the box, but gives you all the dials once you need it.
It has virtually all the features you could want from a modern job queuing system. Including robust concurrency controls, failure retries and alerting, recurring job scheduling, and so much more. In HEY, it replaced no less than 6(!) different Resque gems, as the one integrated solution.
Solid Queue has been meticulously developed within the pressures of a real production environment over the last 18 months, and today it’s running 20 million jobs per day for HEY alone at 37signals.
Solid Queue was created by Rosa Gutiérrez from 37signals.
On top of the trifecta of Solid adapters that makes it possible for SQLite to power Action Cable, Rails.cache, and Active Job, a bunch of work has gone into making the SQLite adapter and Ruby driver suitable for real production use in Rails 8.
At 37signals, we’re building a growing suite of apps that use SQLite in production with ONCE. There are now thousands of installations of both Campfire and Writebook running in the wild that all run SQLite. This has meant a lot of real-world pressure on ensuring that Rails (and Ruby) is working that wonderful file-based database as well as it can be. Through proper defaults like WAL and IMMEDIATE mode. Special thanks to Stephen Margheim for a slew of such improvements and Mike Dalessio for solving a last-minute SQLite file corruption issue in the Ruby driver.
But Rails 8 is not just about the better deployment story and database-backed adapters. We’re also making Propshaft the new default asset pipeline. Propshaft a is dividend from the mission to focus on #NOBUILD as the default path in Rails 7 (and offloading more complicated JavaScript setups to bun/esbuild/vite/etc). As the new asset pipeline it replaces the old Sprockets system, which hails from all the way back in 2009. A time before JavaScript transpilers and build pipelines as we know them today existed. And long, long before we could imagine browsers with stellar JavaScript implementations, import maps, and no constraints from many small files thanks to HTTP/2.
It’s a great example of the need to occasionally pull a fresh sheet of paper and consider a familiar problem from first principles again. And it turns out, in our new #NOBUILD world, the asset pipeline only needs to do two primary things: Provide a load path for assets and stamp them with digests to allow for far-future expiry. That’s basically it. Sprockets did a million other things than that, many of them in a way that had long since fallen out of favor, and from a state of disrepair that had few contributors willing or able to help remedy it.
So we thank Sprockets for 15 years of service, but the future of the asset pipeline in Rails is called Propshaft. And it’s now the default for all Rails 8 applications, though we’ll continue to support Sprockets for existing applications.
Propshaft was created by David Heinemeier Hansson, from 37signals, and Breno Gazzola, from FestaLab.
Finally, making it easier to go to production also means we ought to make it easy to be secure. Rails has been assembling high-level abstractions for the key components of an excellent authentication system for a long time to bring that ease. We’ve had has_secure_password since Rails 5, but also recently introduced generates_token_for :password_reset along with authenticate_by in Rails 7.1. Now, with Rails 8, we’re putting all the pieces together in a complete authentication system generator, which creates an excellent starting point for a session-based, password-resettable, metadata-tracking authentication system.
Just run bin/rails generate authentication and you’ll get basic models for Session and User, together with a PasswordsMailer, SessionsController, and an Authentication concern. All you have to bring yourself is a user sign-up flow (since those are usually bespoke to each application). No need to fear rolling your own authentication setup with these basics provided (or, heaven forbid, paying a vendor for it!).
Rails 8 is dropping just a few months after Rails 7.2, but on top of all these incredible new tools presented above, also includes a wealth of fixes and improvements. Rails has never been firing harder on all cylinders than what we’re doing at the moment. It’s an incredible time to be involved with the framework and an excellent moment to hop on our train for the first time. Whether you’re into #NOBUILD or #NOPAAS or simply attracted to the mission of compressing complexity in general, you’ll be right at home with a community of passionate builders who value beautiful code as much as they do productivity.
I’ve worked on a few Ruby apps in my career at varying scales:
Over all of these Ruby codebases, there’s been a consistent theme:
What do I mean by “breaking things”?
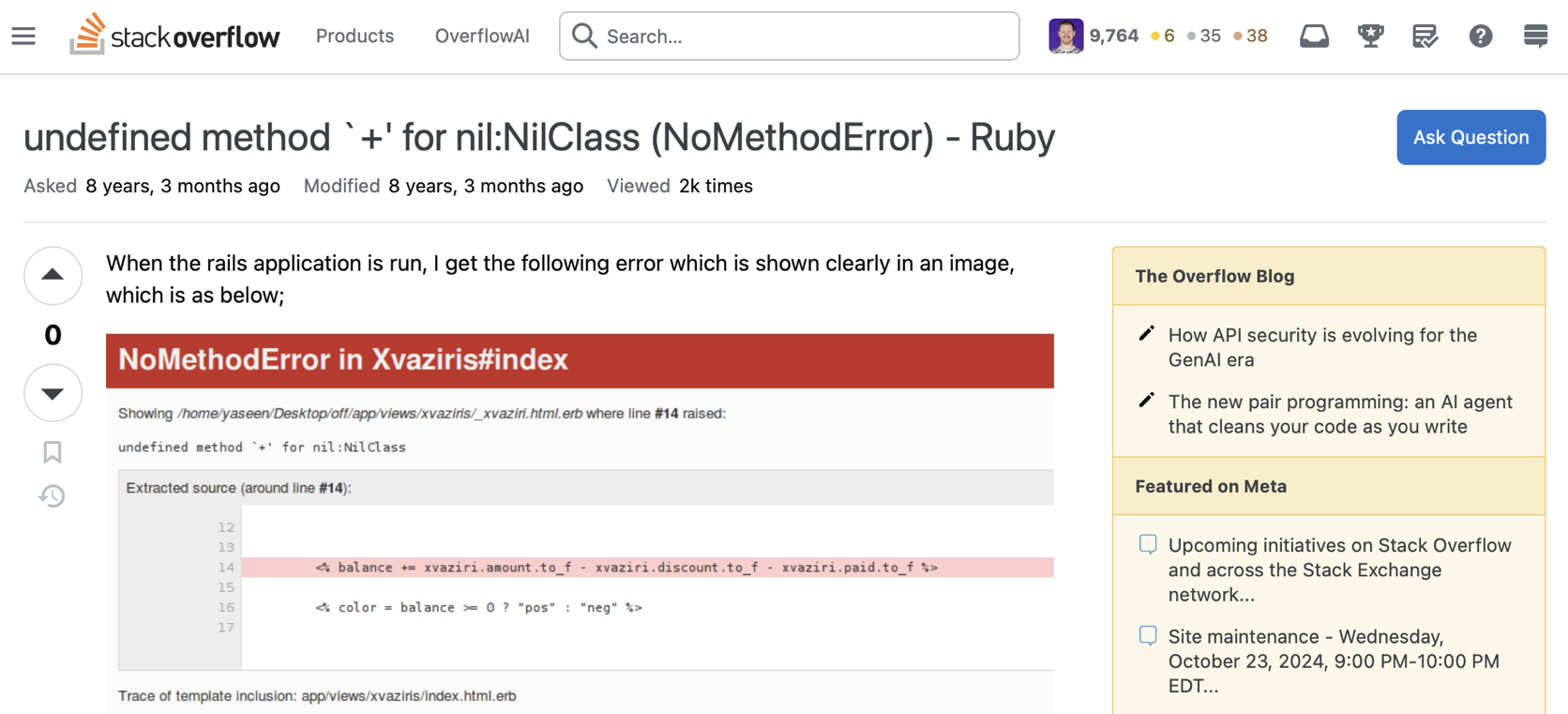
If you’ve been a Ruby developer for any non-trivial amount of time, you’ve lost a non-trivial amount of your soul through the number of times you’ve seen this error. If you’ve worked with a reasonably strict compiled language (e.g. Go, Rust, C++, etc.) this sort of issue would be caught by the compiler and never make it into production. The Ruby interpreter, however, makes it very hard to actually catch these errors at runtime (so they often do make it into production).
This is when, of course, you’ll jump in with “well, of course you just need to…” but: chill, we’ll get to that. I’m setting the scene for:
The solution to these problems is simple, just …
Actually, no, the solution is never simple and, like almost anything in engineering: it depends entirely on what you’re optimising for.
What I’m optimising for (in descending priority):
Ok, enough about principles, what about specifics?
I define “linters” as anything that’s going to help catch issues in either local development or automated test environments. They are good at screaming at you so humans don’t have to.
rubocop: the best Ruby linter.
I generally try to enable as much as possible in Rubocop and disable rules locally when necessary.erb_lint: like Rubocop, but for ERB.
Helps keep your view templates a bit more consistent.better_html: helps keep your HTML a bit more consistent through development-time checks.prosopite: avoids N+1 queries in development and test environments.licensed: ensures that all of your dependencies are licensed correctly.actionlint: ensures that your GitHub Actions workflows are correct.eslint: when you inevitably have to write some JavaScript: lint that too.I add these linters to my Gemfile with something like this:
group :development do
gem "better_html"
gem "erb_lint"
gem "licensed"
gem "rubocop-capybara"
gem "rubocop-performance"
gem "rubocop-rails"
gem "rubocop-rspec"
gem "rubocop-rspec_rails"
end
If you want to enable/disable more Rubocop rules, remember to do something like this:
require:
- rubocop-performance
- rubocop-rails
- rubocop-rspec
- rubocop-rspec_rails
- rubocop-capybara
AllCops:
TargetRubyVersion: 3.3
ActiveSupportExtensionsEnabled: true
NewCops: enable
EnabledByDefault: true
Layout:
Exclude:
- "db/migrate/*.rb"
Note, this will almost certainly enable things you don’t want.
That’s fine, disable them manually.
Here you can see we’ve disabled all Layout cops on database migrations (as they are generated by Rails).
My approach for using linters in Homebrew/Workbrew/the parts of GitHub where I had enough influence was:
When disabling linters, consider doing so on a per-line basis when possible:
# Bulk create BrewCommandRuns for each Device.
# Since there are no callbacks or validations on
# BrewCommandRun, we can safely use insert_all!
#
# rubocop:disable Rails/SkipsModelValidations
BrewCommandRun.insert_all!(new_brew_command_runs)
# rubocop:enable Rails/SkipsModelValidations
I also always recommend a comment explaining why you’re disabling the linter in this particular case.
I define “tests” as anything that requires the developer to actually write additional, non-production code to catch problems. In my opinion, you want as few of these as you can to maximally exercise your codebase.
rspec: the Ruby testing framework used by most Ruby projects I’ve worked on.
Minitest is fine, too.simplecov: the standard Ruby code coverage tool.
Integrates with other tools (like CodeCov) and allows you to enforce code coverage.playwright: dramatically better than Selenium for Rails system tests with JavaScript.
If you haven’t already read Justin Searls’ post explaining why you should use Playwright: go do so now.vcr: record and replay HTTP requests.
Nicer than mocking because they test actual requests.
Nicer than calling out to external services because they are less flaky and work offline.parallel_tests: run your tests in parallel.
You’ll almost certainly get a huge speed-up on your multi-core local development machine.sponsors-maintainers-man-completions.yml for an example of a complex GitHub Actions workflow that opens pull requests to updates files.
Here’s a recent automated pull request updating GitHub Sponsors in Homebrew’s README.md.I add these tests to my Gemfile with something like this:
group :test do
gem "capybara-playwright-driver"
gem "parallel_tests"
gem "rspec-github"
gem "rspec-rails"
gem "rspec-sorbet"
gem "simplecov"
gem "simplecov-cobertura"
gem "vcr"
end
In Workbrew, running our tests looks like this:
$ bin/parallel_rspec
Using recorded test runtime
10 processes for 80 specs, ~ 8 specs per process
....................................................................
....................................................................
....................................................................
....................................................................
....................................................................
....................................................................
....................................................................
......................
Coverage report generated to /Users/mike/Workbrew/console/coverage.
Line Coverage: 100.0% (6371 / 6371)
Branch Coverage: 89.6% (1240 / 1384)
Took 15 seconds
I’m sure it’ll get slower over time but: it’s nice and fast just now and it’s at 100% line coverage.
There has been (and will continue to be) many arguments over line coverage and what you should aim for. I don’t really care enough to get involved in this argument but I will state that working on a codebase with (required) 100% line coverage is magical. It forces you to write tests that actually cover the code. It forces you to remove dead code (either that’s no longer used or cannot actually be reached by a user). It encourages you to lean into a type system (more on that, later).
I define “monitoring” as anything that’s going to help catch issues in production environments.
I’m less passionate about these specific tools than others. They are all paid products with free tiers. It doesn’t really matter which ones you use, as long as you’re using something.
I add this monitoring to my Gemfile with something like this:
group :production do
gem "sentry-rails"
gem "logtail-rails"
end
Well, in Ruby, this means “pick a type system”. My type system of choice is Sorbet. I’ve used this at GitHub, Homebrew and Workbrew and it works great for all cases. Note that it was incrementally adopted on both Homebrew and GitHub.
I add Sorbet to my Gemfile with something like this:
gem "sorbet-runtime"
group :development do
gem "rubocop-sorbet"
gem "sorbet"
gem "tapioca"
end
group :test do
gem "rspec-sorbet"
end
A Rails view component using Sorbet in strict mode might look like this:
class AvatarComponent < ViewComponent::Base
sig { params(user: User).void }
def initialize(user:)
super
@user = user
end
sig { returns(User) }
attr_reader :user
sig { returns(String) }
def src
if user.github_id.present?
"https://avatars.githubusercontent.com/u/#{user.github_id}"
else
...
end
end
In this case, we don’t need to check the types or nil of user because we know from Sorbet it will always be a non-nil User.
This means, at both runtime and whenever we run bin/srb tc (done in the VSCode extension and in GitHub Actions), we’ll catch any type issues.
These are fatal in development/test environments.
In the production environment, they are non-fatal but reported to Sentry.
Note: Sorbet will take a bit of getting used to.
To get the full benefits, you’ll need to change the way that you write Ruby and “lean into the type system”.
This means preferring e.g. raising exceptions over raising nil (or similar) and using T.nilable types.
It may also include not using certain Ruby/Rails methods/features or adjusting your typical code style.
You may hate it for this at first (I and many others did) but: stick with it.
It’s worth it for the sheer number of errors that you’ll never encounter in production again.
It’ll also make it easier for you to write fewer tests.
TL;DR: if you use Sorbet in this way: you will essentially never see another nil:NilClass (NoMethodError) error in production again.
That said, if you’re on a single-developer, non-critical project, have been writing for a really long time and would rather die than change how you do so: don’t use Sorbet.
Well, I hear you cry, “that’s very easy for you to say, you’re working on a greenfield project with no legacy code”. Yes, that’s true, it does make things easier.
That said, I also worked on large, legacy codebases like GitHub and Homebrew that, when I started, were doing very few of these things and now are doing many of them. I can’t take credit for most of that but I can promise you that adopting these things was easier than you would expect. Most of these tools are built with incrementalism in mind.
Perfect is the enemy of good. Better linting/testing/monitoring and/or types in a single file is better than none.
You may feel like the above sounds overwhelming and oppressive. It’s not. Cheating is fine. Set yourself strict guardrails and then cheat all you want to comply with them. You’ll still end up with dramatically better code and it’ll make you, your team and your customers/users happier. The key to success is knowing when to break your own rules. Just don’t tell the robots that.
